Storage
Coming from embeddings, you have a vector. Now the question is how I actually keep it alive in Piramid — on disk, across restarts, through crashes — while still being fast enough to read back at query time. Before getting into the decisions I made, it's worth understanding the landscape of how databases generally solve the storage problem, because my choices only make sense in that context.
How databases store data
At the most fundamental level, a database is just a program that reads and writes bytes to storage devices. The way those bytes are organized — the storage engine — determines almost everything about the system's performance characteristics: read throughput, write throughput, space amplification, recovery time after a crash, and how the system degrades as data grows.
There are two dominant storage engine architectures that most modern databases are built on. Understanding both is useful not because Piramid is built on either, but because the design choices I made only make sense relative to them.
The first is the B-tree (and its variants, primarily B+ trees). A B+ tree stores data in fixed-size pages, typically 4KB or 8KB, organized as a balanced tree of nodes. Leaf nodes hold the actual records or pointers to them; internal nodes hold keys and child pointers used for navigation. Postgres uses 8KB pages and stores rows in heap files — unordered flat files of pages where each page is a slotted array holding row data and a header with a page directory. To find a row, Postgres reads the heap page and scans its slots, or uses a B+ tree index to navigate directly to the right page. The on-disk layout is very stable: pages are written in-place, the tree stays balanced through splits and merges, and the data file doesn't need to be rewritten to stay healthy. The cost is that random writes touch many different pages, and those pages need to be cached in a buffer pool to avoid thrashing the disk.
The second is the LSM-tree (Log-Structured Merge-tree), used by RocksDB, Cassandra, LevelDB, and many others. The core insight is to make all writes sequential by buffering them in an in-memory table (the memtable) and periodically flushing it to an immutable sorted file on disk (an SSTable). Over time you accumulate multiple SSTables at level 0. Background compaction jobs merge and sort these into larger SSTables at progressively deeper levels, discarding deleted and overwritten keys in the process. Reads are more expensive since you may need to check the memtable, bloom filters, and multiple SSTables at different levels, but writes are always sequential, which on spinning disks especially is a dramatic throughput advantage. The tradeoff is write amplification: data gets rewritten multiple times across compaction levels, which increases I/O and wears SSDs faster. The compaction process is also continuous, running in the background at all times.
 B-tree vs LSM-tree — B-trees do in-place page updates with a buffer pool; LSM-trees buffer writes in a memtable and flush to immutable SSTables, merging them in background compaction passes
B-tree vs LSM-tree — B-trees do in-place page updates with a buffer pool; LSM-trees buffer writes in a memtable and flush to immutable SSTables, merging them in background compaction passes
These two architectures represent a fundamental tension:
- B-trees offer stable read performance and in-place updates, at the cost of write amplification from page splits and the need to manage a buffer pool explicitly.
- LSM-trees offer high write throughput via sequential I/O, at the cost of read overhead and ongoing compaction I/O in the background.
Piramid doesn't fit cleanly into either model, and that's intentional. Vectors are written once (or rarely updated), read often during search, and occasionally deleted — which is a fundamentally different access pattern from the workloads these engines were built for. Understanding where a vector database lands relative to these two models is what makes the storage design legible.
On-disk layout
Every collection lives under a path you configure at startup (DATA_DIR). For a collection named my_docs, Piramid creates a set of files that together represent the complete state of that collection:
my_docs.db — the main data file (mmap'd raw byte store)
my_docs.index.db — the offset index: UUID → (offset, length) in the data file
my_docs.vidx.db — the serialized vector index (HNSW graph, IVF clusters, etc.)
my_docs.meta.db — collection-level metadata (vector count, timestamps, config)
my_docs.wal.db — the write-ahead log
The data file is the closest thing to a traditional heap file: a flat, append-oriented binary store of serialized document entries. Unlike a B+ tree page file, there's no fixed page size and no tree structure. Vectors are written sequentially at the end of the file as they arrive, and their byte locations are tracked in a separate in-memory and on-disk index (my_docs.index.db), which maps each document UUID to an (offset, length) pair. A lookup for a specific document goes: read the offset index to find the byte range, then read those bytes from the data file and deserialize. There's no page directory, no slot array, no internal tree to navigate, just a flat file and a map telling you where things are.
This is simpler than a B+ tree heap, and for the access patterns I'm targeting, that simplicity is a feature not a compromise. Documents are written once and rarely touched again; point lookups by UUID are satisfied by the offset index; range scans by vector similarity are handled entirely by the vector index, not by scanning the data file at all. The data file is basically a dumb append log that you consult after the ANN index has already done the interesting work.
The vector index file holds the ANN structure (HNSW graph adjacency lists, IVF centroids, etc.) serialized separately. This separation is important: the data file and the vector index have completely different access patterns and different rebuild costs. The data file is append-heavy and can be written to incrementally. The vector index is rebuilt from scratch during index rebuild operations or compaction, because rebuilding an HNSW graph incrementally from a corrupted state is hard to do correctly. Keeping them separate lets each evolve and persist independently, and means a corrupt vector index doesn't invalidate your raw data.
Memory-mapped I/O vs the buffer pool
How a database moves data between disk and RAM is one of its most consequential design decisions, and it's an area where there's genuine disagreement among database designers.
Traditional databases like Postgres manage their own buffer pool: a fixed-size region of memory divided into pages, with an explicit clock-sweep or LRU eviction policy, dirty page tracking, and write ordering controlled by the database itself. The database calls read() and write() syscalls to move pages in and out, bypassing the OS page cache entirely (using O_DIRECT on Linux). This gives the database precise control: it knows which pages are dirty, it can force write ordering (flushing WAL before dirty pages, for instance), and it can implement eviction policies tuned to database access patterns rather than general-purpose ones. The tradeoff is complexity — a buffer pool manager is a substantial piece of code, and the fact that you're maintaining a second cache in userspace while the OS maintains its own potentially doubles the memory used for the same data.
The alternative is mmap, which lets the OS page cache serve as the buffer pool. When you call mmap on a file, the OS maps the file's byte range into the process's virtual address space. Pages start unmapped; the first access to any address in the range generates a page fault, the OS reads the 4KB page from disk, inserts it into the page cache, updates the page table entry, and resumes your code. Subsequent accesses to the same address hit RAM directly with no syscall cost, they're just memory reads from the process's perspective. Under memory pressure the OS evicts cold pages using its LRU-approximate page replacement algorithm. The application sees a flat byte slice; all the paging machinery is invisible.
The advantage is simplicity: no buffer pool code to write, efficient random access, and sequential reads benefit from the kernel's readahead heuristics. The disadvantage is that you give up control. The OS doesn't know that your WAL needs to flush before your data pages; it doesn't know which pages you'd prefer to keep hot; it can't prevent a page from being evicted at an inopportune time. For a database with strict write-ordering requirements, this loss of control matters.
I went with mmap for the data file by default, and the decision was partly about where I want to spend my engineering time. A buffer pool gives you explicit control over caching, eviction, and data integrity, but it's a substantial piece of code to write and maintain alone. Since my main goal right now is improving vector search performance, I don't want to build an entire buffer management system that might get overwritten by a future caching layer anyway. The write ordering requirements are handled by the WAL (discussed below) rather than by careful page flushing, so the loss of dirty page control is less critical. Piramid's primary bottleneck is ANN search, which happens entirely in the vector index in memory, not page I/O — so the simplicity of mmap is a reasonable tradeoff. The use_mmap: false path falls back to heap allocation backed by regular file I/O if you need more control.
One additional detail on growth: when a collection's data file needs to expand, I unmap it, call ftruncate to extend the file to twice the required size, and remap. The doubling factor amortizes the remap cost across future inserts, the same geometric growth strategy a Vec uses to avoid reallocations.
 Memory-mapped I/O — mmap projects the file's byte range into the process's virtual address space; the OS page cache handles faulting pages in on first access and evicts them under memory pressure
mmap maps the file into the process's virtual address space. First access triggers a page fault; the OS loads the 4KB page and subsequent accesses read directly from RAM. No syscall, no explicit read.
Memory-mapped I/O — mmap projects the file's byte range into the process's virtual address space; the OS page cache handles faulting pages in on first access and evicts them under memory pressure
mmap maps the file into the process's virtual address space. First access triggers a page fault; the OS loads the 4KB page and subsequent accesses read directly from RAM. No syscall, no explicit read.
Warming
This one is a practical consequence of how mmap works. When I load a collection on startup, neither the data file nor the vector index file is resident in RAM yet; they're backed by the page cache, but each page needs a fault to get there. If the server starts accepting traffic immediately, the first requests pay page fault latency on every cold access, up to several milliseconds per fault if the page cache is cold after a restart.
The solution is to explicitly warm the files before the server opens for traffic, by touching every 4KB-aligned page in sequence:
const PAGE: usize = 4096;
let mut offset: usize = 0;
while offset < len {
let byte = mmap[offset];
std::hint::black_box(byte);
offset = offset.saturating_add(PAGE);
}
std::hint::black_box prevents the compiler from optimizing the read away as dead code. This loop is essentially a manual madvise(MADV_WILLNEED), telling the kernel to load all of this into RAM now, except in portable Rust rather than a Linux-specific syscall. For large collections this adds a few seconds to startup, but after it completes every access to the data is a RAM hit. The tradeoff is deliberate: predictable latency during live traffic is worth a slower startup.
The write-ahead log
The WAL is one of the most important ideas in database engineering, and I have personal reasons for taking it seriously. During a summer freelance job, I had a local SQLite .db file get deleted — everything from that session was just gone. No recovery, no log, nothing. That experience made it viscerally clear that a database has to be able to wake up from the dead and reconstruct what happened. The principle is simple: before you modify data files, write a log record describing the change. Crash recovery is then just replaying the log.
The theoretical framework behind WAL design is the ARIES protocol (Algorithm for Recovery and Isolation Exploiting Semantics), developed at IBM in the early 1990s. ARIES formalizes WAL under two key policies — which I think of as the "what can you defer?" question for both writes and reads:
- No-force: dirty pages do not need to be flushed to disk before a transaction commits. The WAL log alone is sufficient to guarantee durability, so the data files can be written lazily. This is what makes write-heavy workloads fast; you avoid synchronous page flushes on the commit path.
- Steal: a dirty page from an uncommitted transaction can be evicted from the buffer pool to disk before that transaction commits. This gives the buffer pool maximum flexibility but requires undo log records in case the transaction rolls back.
Aries uses both undo and redo log records as a result of the steal/no-force combination. It assigns each log record a Log Sequence Number (LSN), a monotonically increasing identifier. Each data page stores the LSN of the most recent log record that modified it. During recovery, ARIES runs three passes: an analysis pass to determine which transactions were active at crash time, a redo pass that replays all logged changes from the last checkpoint forward (reapplying both committed and uncommitted changes to reconstruct the crash-time state), and an undo pass that rolls back changes from transactions that were in-flight at the time of the crash.
I kept Piramid's WAL simpler than full ARIES — intentionally. It uses a redo-only log. Each entry is a complete logical record — the full vector, text, metadata, and ID — not a page-level physical diff. There's no undo pass because Piramid doesn't have multi-statement transactions that need rollback. On recovery it replays all entries with seq > last_checkpoint_seq in order, which is sufficient to reconstruct the collection state.
The four entry types in the log are:
WalEntry::Insert { id, vector, text, metadata, seq }
WalEntry::Update { id, vector, text, metadata, seq }
WalEntry::Delete { id, seq }
WalEntry::Checkpoint { timestamp, seq }
The durability knob is the sync_on_write config. flush() drains the userspace BufWriter to the kernel buffer, fast, but a power loss can still drop buffered kernel writes. fsync pushes all the way to the storage device, slow (1–10ms per call depending on the device), but truly durable. With sync_on_write: false (the default), writes are fast at the cost of a small data loss window on power failure. With sync_on_write: true, every write waits for the device to acknowledge the flush. The right choice depends on whether you're running on a server with a UPS, an NVMe with power-loss protection, or a laptop.
 Write-ahead log — every mutation is appended to the WAL before touching the data files; on recovery the log is replayed forward from the last checkpoint to reconstruct any changes that didn't make it to disk
Every write hits the WAL first. On crash, recovery replays the log from the last checkpoint forward to reconstruct any changes that didn't make it to the data files.
Write-ahead log — every mutation is appended to the WAL before touching the data files; on recovery the log is replayed forward from the last checkpoint to reconstruct any changes that didn't make it to disk
Every write hits the WAL first. On crash, recovery replays the log from the last checkpoint forward to reconstruct any changes that didn't make it to the data files.
Checkpoints and WAL rotation
The WAL would grow forever without a mechanism to bound its size. That mechanism is the checkpoint — and the concept is simpler than the recovery literature makes it sound. A checkpoint is a moment when the database writes its current in-memory state to the durable data files, records that position in the log, and says: everything before this point is redundant for recovery.
In Postgres, this is a fuzzy checkpoint: dirty pages are flushed incrementally over a configurable spread period to avoid a spike of I/O, and the checkpoint record in the WAL marks the range of LSNs that were active during the checkpoint. Recovery only needs to redo from the oldest dirty page's LSN at the time the checkpoint started, not from the checkpoint record itself, which requires careful tracking of active transactions. This makes Postgres checkpoints more complex but avoids a write surge.
I went with a simpler sharp checkpoint: at checkpoint time, I serialize the full in-memory state (the offset index, vector index, and collection metadata) to their respective .db files, write a Checkpoint entry to the WAL, and rotate the WAL to a fresh file. Everything before the checkpoint sequence is now redundant for recovery. No fuzzy spreading, no active transaction tracking — just a synchronous snapshot of the collection state.
The checkpoint is triggered by two independent conditions: every checkpoint_frequency operations (default: 1000), or every checkpoint_interval_secs seconds (disabled by default). The operation counter fires first in write-heavy workloads; the time interval is a safety net for collections that receive infrequent writes but still benefit from periodic durability snapshots.
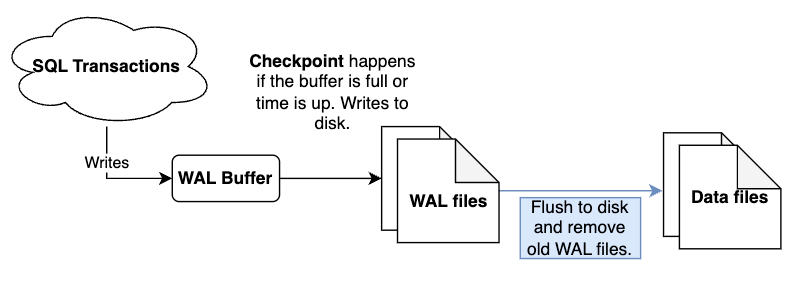 WAL rotation timeline — a horizontal timeline showing WAL entries accumulating, a checkpoint marker where all in-memory state flushes to .db files, then the log rotating to a fresh file with the sequence continuing
WAL rotation timeline — a horizontal timeline showing WAL entries accumulating, a checkpoint marker where all in-memory state flushes to .db files, then the log rotating to a fresh file with the sequence continuing
The cost is real: for large HNSW graphs, serializing the vector index is expensive in both time and I/O. This is why the default interval is 1000 operations rather than something lower. The fast preset raises it to 10000; high-durability mode drops it to 100 and also flips sync_on_write: true. These presets map roughly to the LSM-tree levels-of-durability philosophy, where you're explicitly trading write throughput against recovery latency and data loss window.
Compaction
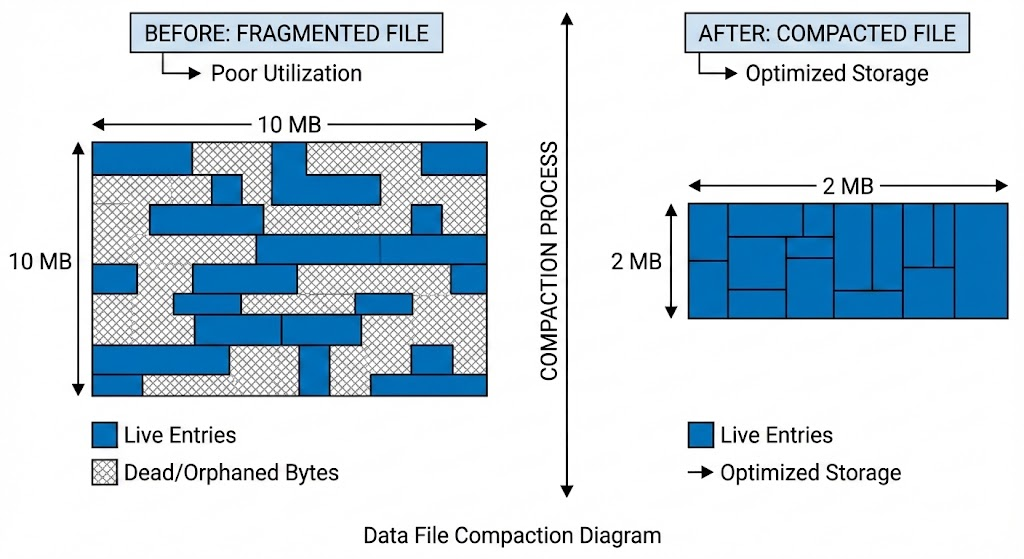 Data file compaction diagram — before: the file with live entries (solid) interspersed with dead/orphaned bytes (hatched), labeled "fragmented"; after: a tightly packed file with only live entries and a much smaller file size
Data file compaction diagram — before: the file with live entries (solid) interspersed with dead/orphaned bytes (hatched), labeled "fragmented"; after: a tightly packed file with only live entries and a much smaller file size
In an LSM-tree, compaction is a continuous background process: SSTables at each level are periodically merged and rewritten to eliminate deleted keys, expired entries, and overwritten versions. The benefit is that read amplification stays bounded, so you never have to consult too many SSTables to answer a query, and reclaimed space is freed gradually rather than accumulating. The cost is ongoing write amplification; data is physically rewritten multiple times as it moves down the tree levels.
In a B+ tree-based system like Postgres, space reclamation is handled by VACUUM: a separate process that walks heap pages, marks dead tuple space as reusable, and updates the free space map. Updates and deletes in Postgres don't overwrite in place; they write a new version and mark the old one dead (MVCC), so VACUUM runs asynchronously to reclaim the dead space without blocking reads.
My approach is closer in spirit to a compacting B-tree (like LMDB's copy-on-write tree) than to either of the above. When a document is deleted, its UUID is removed from the in-memory offset index, but its bytes remain in the data file. Updates write a new entry at a new offset and remove the old UUID→offset mapping; the old bytes are orphaned. Over time this is just fragmentation — you're paying disk space for dead bytes you'll never read.
Compaction resolves this with a full rewrite. It reads all live documents from the current mmap, truncates the file back to initial size, remaps, clears all indexes and caches, then reinserts every live document through the normal insert path. After reinsertion it saves the index, vector index, and metadata to disk, then rotates the WAL. The result is a clean file with zero fragmentation and no dead entries.
The cost is proportional to the number of live documents and is blocking at the collection level, so no reads or writes can proceed against that collection during compaction. This is quite different from LSM-tree compaction, which runs entirely in the background and doesn't block reads. The tradeoff I made here is simplicity over operational transparency: compaction is something you trigger explicitly (or schedule during low-traffic windows) rather than something that happens automatically. For collections that are mostly append-only, compaction frequency can be very low or zero. For collections with high deletion or update churn, it matters more.
In-memory caches
Alongside the mmap, Piramid maintains two in-memory caches per collection: a vector cache (HashMap<Uuid, Vec<f32>>) and a metadata cache (HashMap<Uuid, Metadata>). These complement the OS page cache rather than replacing it — they operate at the application level, keyed on UUID, and bypass the deserialization step entirely on a hit.
The distinction from a buffer pool is important. A buffer pool manages raw pages and knows about page layout, slot arrays, and dirty tracking. These caches operate at the document level: once a vector is deserialized from the mmap into a Vec<f32>, it's stored here and subsequent lookups return the parsed object directly. It's a higher-level cache that avoids both the page fault cost (if the page isn't resident) and the deserialization cost (even if it is).
The caches aren't LRU-evicting by default — they grow unboundedly until max_memory_per_collection is hit, at which point they're cleared entirely. This is coarser than LRU: you lose all cache warmth at once rather than gracefully evicting cold entries. It's a conscious simplicity tradeoff. A proper LRU per collection adds complexity, and for most collections that fit comfortably in memory, unbounded growth with a hard cap is fine.
The total memory usage of a collection accounts for all of this:
where is the embedding dimension, 16 bytes is the UUID key size, and bytes is the float32 vector. For a fully-cached collection of vectors at :
Just for the vector cache. That's before the mmap, the HNSW graph (which adds roughly 30–60 bytes per node depending on the degree parameter), and the metadata. The memory limit config exists precisely because these numbers compound fast and an unconfigured collection will happily consume all available RAM on a large dataset.