The Evolution
I was talking with a friend from my student org one day about building something ambitious, we were throwing around ideas and landed on: what if we just built a database? Not for any particular reason at first, just because it seemed like the kind of project that would force us to understand systems at a level most people never reach. what if we built one that was genuinely fast?
How I got here
By that point I’d been deep in AI for a while, and my path into it was unusual. Most people go from theory to applications, then build something with them. I went the opposite direction. I started building AI agents, which pulled me into RAG systems, which pulled me into embeddings and transformers. Each layer dragged me deeper into the one below it. By the time I was studying transformer architectures in DAT 494 (Advanced Deep Learning) at ASU and building language models from scratch, I already had practical intuition from shipping real systems.
SparkyAI was the project where I dove into reranking mechanisms, advanced retrieval variations, and read a stack of research papers over winter break (my paper summaries live here). I was a heavy Qdrant user by then, my go-to vector database for every hackathon I built and won. I knew the API inside and out, had read their engineering blogs, and understood the configuration at an advanced level.
I’d also just built Kaelum (LATS-based agentic router with a reward model and online policy selection), which taught me how neural network routing works. Between that, I had this realization of where instead of building smart applications on top of dumb databases, what if the database itself was natively smart? Auto-adjusted search mechanisms, intelligent index selection, a system that understands its own workload rather than being a manual machine. With the agentic boom happening, this felt like the right direction.
The Plan
I was jotting down on Excalidraw, I could think of: architecture, data flow, storage layout, indexing strategies, search paths, API shape, CLI flow, caching, collection lifecycle, consistency, durability, backup/restore, observability, deployment, scaling. At every step I noticed how sequential it was.
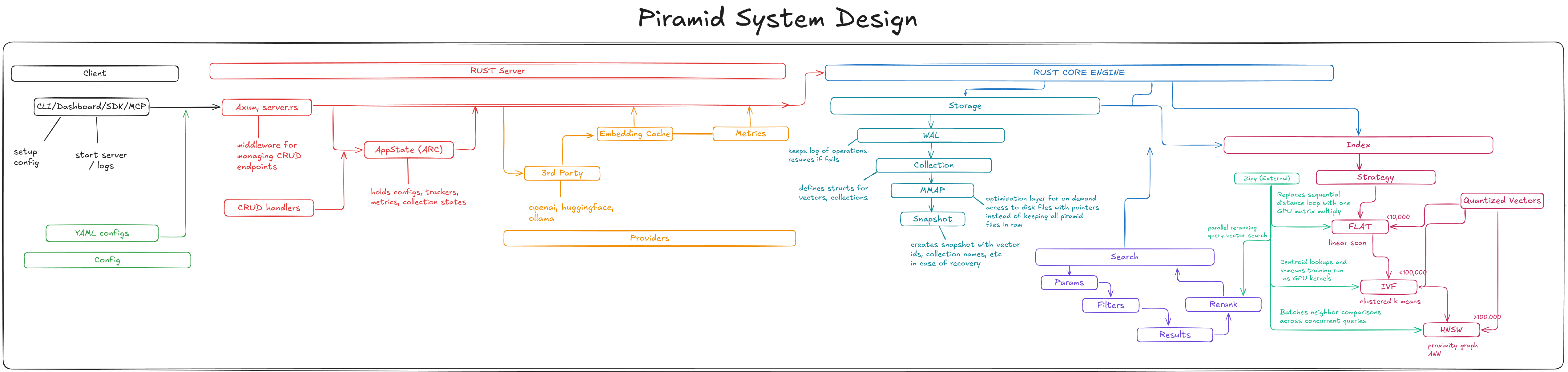 Diagram
Diagram
I read Designing Data-Intensive Applications, database survey papers, blog posts from Qdrant, Pinecone, and Weaviate. I spent bus rides and time between classes just consuming material about storage engines, HNSW graphs, WAL protocols, and consistency models.
Dead ends
The biggest dead end was code organization than what i thought. I rewrote the file structure multiple times, ripping out entire modules because they didn’t make sense in context. I also learned about naming conventions in software engineering and settled on snake_case with categorical purpose-based folder structures. It sounds mundane, but when you’re building a system this large alone, the codebase has to make sense to you months later or you’re dead.
The constraints
This has taken about a month so far, worked on mainly during weekends. I’m building this completely alone -- the Rust core, the CLI, the REST API, the Python SDK, the npm package, this blog, and the website, while simultaneously working in two research labs, a part-time SWE job, running software at AIS and SoDA and college.
When I chose mmap over building a buffer pool, or started with int8 quantization instead of every precision format, or shipped with two embedding providers instead of five, those were all scope decisions made by someone with about 10 hours a week.